
La era de las máquinas lectoras[1]
Primera parte
José Antonio
Millán
.
Historia de la elaboración y edición de este artículo.
Está sujeto a la licencia de Creative Commons "Reconocimiento-No comercial-Compartir bajo la misma licencia 2.5 España" (http://creativecommons.org/licenses/by-nc-sa/2.5/es/deed.es).
Puede comentarlo en el blog de Libros & Bitios.
La ilustración que encabeza este artículo procede de MMOArt, y proviene de Google Blogoscoped.
Un fantasma recorre el universo de los textos. Un ejército de máquinas, a las que aludimos con metáforas zoológicas (arañas) o mecánicas (cosechadoras), merodean por la Red, leen nuestros textos, e incluso atisban por encima del hombro mientras escribimos.
¿Para qué lo hacen? ¿Para espiarnos? A veces... ¿Para comprendernos mejor? Ciertamente. ¿Para ayudarnos? Eso dicen...
I
En el universo de la World Wide Web las máquinas (los ordenadores, o mejor dicho, sus programas) saltan constantemente de página en página a través de los enlaces, escudriñan su contenido y almacenan cada palabra y cada combinación. De esa forma, cuando les preguntamos (por poner un ejemplo): ¿dónde se habla de Hércules?, pueden contestarnos: aquí y allá...
Pero los buscadores también leen los textos que tienen los enlaces, y así se enteran de qué creen los autores (de páginas web, de cualquier documento accesible en la Red) que tratan las páginas a donde remiten...[2].
Precisamente esa lectura de enlaces es la responsable de algunos de los hallazgos más asombros de los buscadores: encontrar lo que no está... Por ejemplo, la búsqueda de gentuza en Google:
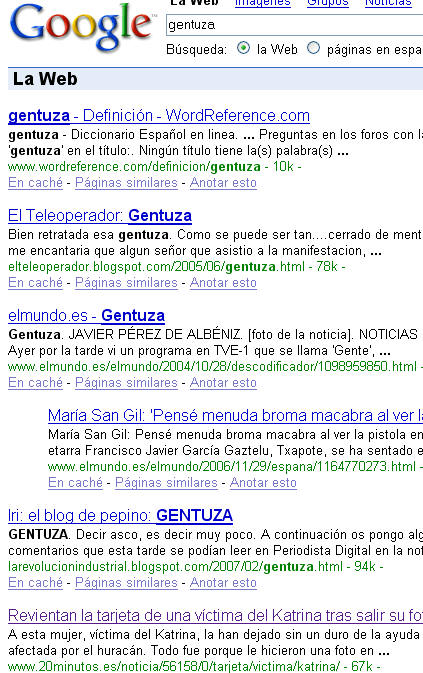
me llevó a esta noticia[3],

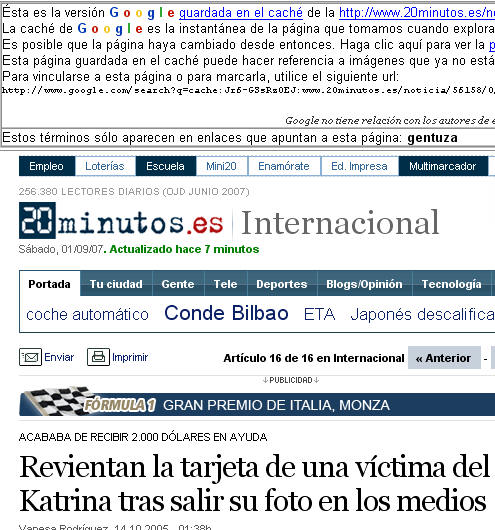
El texto (como advierte el buscador: "Estos términos sólo aparecen en enlaces que apuntan a esta página") no contiene la palabra en cuestión[4]:
Pero hay otras formas en las que las máquinas nos leen. Por ejemplo: cuando intermedian en los artefactos (hadware) que usamos para escribir. Ese es el caso de los softwares espías residentes en un ordenador (como Keystroke Spy[5]), que supervisan todas las pulsaciones del teclado, y avisarán por email cuando su usuario teclee algo de interés[6].
II
Ocasionalmente, las máquinas también escriben (o, para no exagerar: editan, ponen en contacto textos diversos). Ocurre, por ejemplo, cuando colocan dentro de las páginas web anuncios relacionados con su tema (que es lo que hace Google Adwords[7]).
Para ello tienen que haber leído su contenido. Por ejemplo, en una página que analiza unos carteles amenazadores[8] aparecen estos anuncios[9]:
-
El centro del accidentado. Ayuda jurídica para víctimas de accidentes.
-
Chistes de abogados
-
Problemas con alquileres
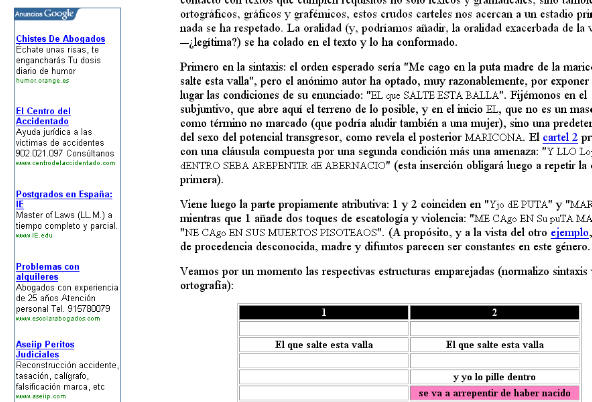
¿Por qué? El texto contenía términos como amenaza, insulto, violencia, transgresor o merodeador, junto a expresiones como "me cago en sus muertos". Los insondables algoritmos de Google Adwords han determinado que (entre los temas de publicidad que administran) los relacionados con accidentes, abogados y problemas eran los más pertinentes...
(Interludio filosófico)
Este tipo de comportamientos nos podría llevar a la siguiente cuestión. Sí: las máquinas leen nuestras páginas web, pero, ¿las entienden? En realidad, esto es una variante del Test de Turing[10]. Como se recordará, en dicha prueba un humano conectado a un terminal exclusivamente textual (tipo chat) debe determinar, sólo a través del diálogo, si al otro lado hay una máquina o un ser humano.
Uno dice "¡Gentuza!", y el buscador contesta: "Sí, como esos que estafaron a una víctima del Katrina...". Uno escribe "amenaza, violencia, transgresor", y los anuncios corean: "abogados, accidentes, problemas". ¿Nos están entendiendo las máquinas? Bueno: lo suficiente como para echarnos una mano. Y el éxito de los buscadores y de los programas de anuncios contextuales parecen indicar que lo logran...
Hay en marcha sistemas todavía más sofisticados. Por ejemplo: un programa que analiza, en un foro sobre valores bursátiles, cuál es la opinión generalizada sobre cuáles van a subir y cuáles a bajar. Es el Community Sentiment de Yahoo[11]. Un análisis de este estilo exige manejar un número considerable de variables semánticas y pragmáticas.

Pero hay que tener en cuenta que las máquinas no sólo están leyendo nuestras páginas web: también leen nuestros diarios (o blogs) o nuestro propio correo (en sistemas como Gmail[12]). Y actúan en consecuencia; si recibimos un email que contiene la palabra México pondrán a su lado anuncios relacionados:
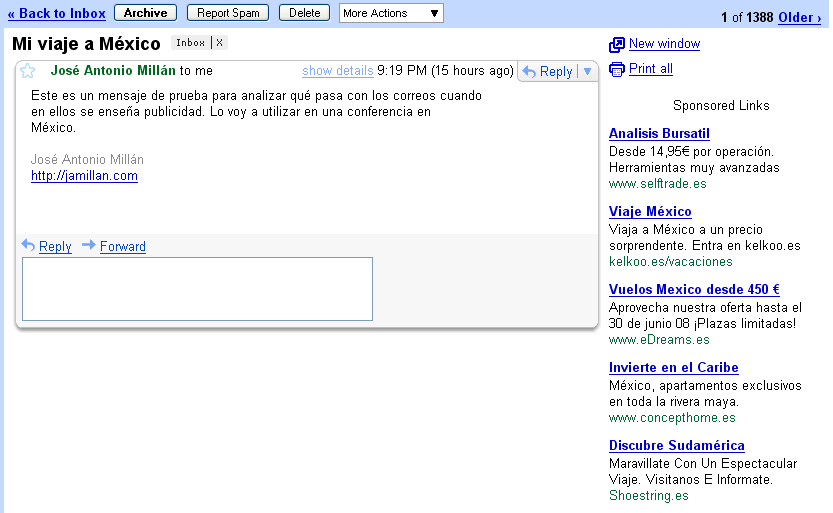
También leen nuestras notas personales (Google Bloc de notas[13]), nuestra escritura manuscrita en una agenda electrónica (a través de programas como PenReader[14]). Si además parece que están enterándose, ¿no supone esto un problema?
La verdad es que sí, pero también nuestros secretarios (o secretarias) leen nuestra correspondencia, y a ellos dictamos nuestras cartas[15]. Digamos que quien confía en ayudas externas (ya sean de carne y hueso o de código) debe atenerse a las consecuencias...
III
Y en este momento nos surge un tema de especial interés. Si las máquinas nos leen, ¿no habrá que tenerlas en cuenta cuando escribimos? La respuesta es claramente que sí: el autor o editor de cualquier material en la Web tiene que favorecer que le lean las máquinas, so pena de comprometer su propia difusión.
Un ejemplo particularmente ilustrativo es el de las licencias Creative Commons. Cada una de ellas tiene tres versiones:
-
el resumen, legible por humanos[16]. Dice cosas como:
-
el código legal, legible por abogados[17]; éste es su comienzo:

-
el código digital, legible por máquinas[18]:
<rdf:RDF xmlns="http://creativecommons.org/ns#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<License rdf:about="http://creativecommons.org/licenses/by/2.5/es/">
<permits rdf:resource="http://creativecommons.org/ns#Reproduction"/>
<permits rdf:resource="http://creativecommons.org/ns#Distribution"/>
<requires rdf:resource="http://creativecommons.org/ns#Notice"/>
<requires rdf:resource="http://creativecommons.org/ns#Attribution"/>
<permits rdf:resource="http://creativecommons.org/ns#DerivativeWorks"/>
</License> </rdf:RDF>
Este caso refleja bien las complejidades de la autoría/edición en la Web. Una norma general de redacción es tener en cuenta al destinatario de un texto para ajustar su nivel, y eso justifica la diferencia entre el "código legal" y el "resumen": sus receptores son, respectivamente, el abogado y el lego en la materia. Pues bien, además de estas cuestiones (comunes con cualquier texto, esté o no en la Red), tenemos otra añadida.
El código digital está destinado a ser leído por sistemas automáticos. En el caso de Creative Commons, se ha incluido para informar a los buscadores que quieran localizar contenidos con determinados tipos de licencia. Las personas no tienen por qué entenderlo, y ni siquiera leerlo: el texto no está visible en la página.
Al igual que este código, en las páginas web hay muchos elementos cuyos destinatarios son las máquinas: los ficheros robots.txt[19], los metatags, y las palabras que se incluyen para forzar el spamdexing[20]. El webmaster (de ingenio aunque tramposo) que llena de palabras prometedoras la parte inferior de su página, y las escribe en el mismo color del fondo para que no se lean en la pantalla, sabe bien que no busca lectores humanos... En el terreno de la edición científica, los metadatos son un elemento básico del texto.
Y una última, pero importante consecuencia, para aquellos que escriben o editan en la Web: cada enlace es un voto a una página. Y mediante el texto específico que enlazamos estamos diciendo algo sobre la página de destino no sólo a nuestros lectores humanos, sino, sobre todo, a las máquinas.
[1] Este texto comenzó como una conferencia en el Seminario Litterae de septiembre del 2007. Gracias a Antonio Castillo, Vanessa de Cruz y Emilio Torné por su invitación a participar. Agradezco a Javier Candeira por la ayuda para su preparación. Gracias a la invitación de Karim Gherab se convirtó en un artículo para Arbor. La versión actual se ha beneficiado de la presentación en varios foros: agradezco en especial a Ernesto Priani la invitación al Cuarto Foro de Edición Digital de México.
[2] El mejor texto sobre El modus operandi de los buscadores (o sea, de Google) sigue siendo el de Javier Candeira, "La Web como memoria organizada", en Revista de Occidente (Madrid), marzo del 2001 (versión electrónica en http://jamillan.com/para_can.htm).
[3] Búsqueda realizada el 14 de noviembre del 2007. 20 minutos, "Revientan la tarjeta de una víctima del Katrina tras salir su foto en los medios", 14 de octubre del 2005 (http://www.20minutos.es/noticia/56158/0/tarjeta/victima/katrina/).
[4] El hecho de que Google se dejara guiar por el contenido de los enlaces llevó al fenómeno de la "Google bomb"; desgraciadamente hoy parece que está inhabilitada por el buscador (http://en.wikipedia.org/wiki/Google_bomb).
[6] Los programas de espionaje también pueden registrar el ruido del teclado, y a partir de él deducir qué se está escribiendo (http://www.securitysolutionsmagazine.com/Articles/SSM38.pdf, pág. 22).
[9] A 13 de noviembre del 2007: los anuncios pueden cambiar cada vez que se accede a la página.
[10] A. M. Turing (1950) "Computing Machinery and Intelligence", en Mind 49: 433-460 (http://cogprints.org/499/0/turing.html).
[15] El rey de Aragón Pedro IV el Ceremonioso (siglo XIV) instituyó por primera vez la comunicación escrita para un gobierno peninsular, y también el archivo de los documentos reales. Se rodeó de una red de secretarios y escribanos, e incluso uno de ellos debía dormir por la noche en sus aposentos, "por si le venía la necesidad de escribir". Pero cuando quiso mantener secreto un tratado con el rey de Castilla lo escribió de su puño y letra. Véase Francisco M. Gimeno Blay, Escribir, reinar. La experiencia gráficotextual de Pedro IV el Ceremonioso (1336-1387), Madrid, Abada editores, 2006.
[18] Contenido en el código fuente de http://creativecommons.org/licenses/by/2.5/es/deed.es.
[19] http://www.webrecursos.com/pages/promo/promobot.htm. Curiosamente, una de las funciones de los robots.txt puede ser la indicación "No me leas"...
[20] Véase mi artículo "El libro de mil millones de páginas. La ecología lingüística de la Web", en Revista de Libros (Madrid), nº 45 (septiembre del 2000), y versión web en http://jamillan.com/ecoling.htm.
Primera presentación oral en Litterae, septiembre del 2007
Primera versión escrita, diciembre del 2007, publicada en la revista Arbor, número 737,
aparecido en mayo del 2009
Presentado en
el Cuarto
Foro de Edición
Digital, México, 20 de junio del 2008
Publicado en Arbor, mayo del 2009
Publicación en esta web, 22 de septiembre del 2009
Correcciones: 23 de septiembre del 2009