![]()
El negocio digital del espańol
y cómo nos quedamos sin él
José Antonio Millán
English version
(modified):
"How much is a language worth"
Invited presentation in:
Language diversity in the information society.
International colloquium organized by the French commission for the UNESCO in
cooperation with the UNESCO and the Agence intergouvernementale de la Francophonie and
with the support of the Ministry for Foreign Affairs and the Ministry for Culture and
Communication.
Paris, March, 9 and 10, 2001. Program.
Colloquium website
Advertencia: Un estudio como este, que combina numerosos tipos de
datos con proyecciones y estimaciones, y que irrumpe en un terreno metodológicamente
complejo, no puede sino ser perfeccionable. El autor agradecerá cualquier observación
que se realice sobre él. Remítanla a
portada arroba jamillan.com
Y otra: Este artículo se elaboró a lo largo de los meses de marzo-septiembre del 2000. Las URLs externas (en rojo) pueden haber cambiado de contenido desde su consulta en ese periodo, o incluso haber dejado de existir.
La versión inicial de este artículo (aquí ligeramente modificada) apareció publicada en el extraordinario "La sociedad de la información" de la revista Politica Exterior, Madrid, invierno 2000/2001. Redacción
[1] Agradezco su
colaboración en la discusión de distintos aspectos a Tomás Baiget, Jesús González
Barahona, Rafael Millán, Javier Candeira, Álvaro del Castillo, Daniel Prado, Lidia
Cámara, Rodolfo González, Héctor Piccoli, Chimo Soler y Xosé Castro. Gracias a
Esteban González Pons y a Política Exterior por la invitación inicial a
escribir este artículo.![]()
Desde hace muchos siglos se habla de la riqueza que supone la lengua espańola, "un habla", decía a finales del siglo XVI el poeta Francisco de Medina, "tan propia en la significación, tan copiosa en los vocablos"... Y sin embargo, somos "tan descuidados o tan ignorantes que dejamos perderse a este raro tesoro que poseemos"
[2]. Don Francisco hablaba de las calidades expresivas de la lengua, no de su interés comercial, pero si (con voluntario anacronismo) leemos hoy sus palabras en un sentido económico, sólo podremos darle la razón...En estos últimos tiempos se reconoce crecientemente el peso económico de la enseńanza de espańol a los extranjeros, la importancia del prestigio de nuestra lengua y cultura para atraer un turismo que es uno de los pilares de nuestra economía, la existencia de un mercado de cientos de millones de personas que hablan espańol (al que suministrar productos editoriales o información), la pujanza de la minoría hispanohablante en EEUU...
Pero al lado de estos procesos económicos que se resuelven en grandes movimientos de átomos (libros espańoles que saltan a América, estudiantes japoneses que viajan a Salamanca, etc.), están las corrientes digitales que caracterizan la economía actual. La mundialización del mercado ha subrayado un hecho del que ya se tenía conciencia, aunque con un alcance limitado: que las personas que comparten una lengua constituyen de hecho una comunidad. Comparten producciones y consumos culturales, pero también el acceso a bienes y servicios: a los hispanohablantes se nos podrá vender discos o viajes vía Internet, pero mayoritariamente habrá de hacerse en espańol. A esto se une otro factor importante: que gran parte de la actividad basada en la lengua (información, consulta y referencia, edición, traducción, redacción...) se ha ido pasando también al medio digital.
En este artículo voy a centrarme precisamente en ese sector oculto: los valores ańadidos lingüísticos que impregnan productos y servicios digitales; es decir: la aportación de lo que se conoce como industrias de la lengua a la economía digital.
Mi tesis es que estos servicios lingüísticos ocultos (pues normalmente no afloran como productos independientes) tienen una gran importancia económica, que voy a intentar cuantificar. A continuación voy a intentar discernir en qué manos acabará ese negocio.
Hacer con la lengua, hacer en la lenguażQué servicios lingúísticos o mediados por la lengua nos va a proporcionar el medio digital? Como introducción (novelesca, pero no irreal), podemos imaginarnos esta escena del próximo futuro.
La acción transcurre en Sevilla o Buenos Aires, mediados de la década del 2000. Es por la mańana; el Usuario entra en la habitación.
AGENTE AUTOMÁTICO: Buenos días. Le recuerdo, como me indicó, que dentro de una semana es el cumpleańos de Marta.
USUARIO (mientras se pasea con una taza de café en la mano). Muy bien: cómprale algo para leer:sobre jardinería, o sobre cómo preparar conservas. Consulta con su agente para cerciorarte de que no lo tiene. Y prepara una carta de felicitación... żQué hay en el correo?
AA: Recordará que había pedido un aplazamiento en la entrega del proyecto hasta el día 20. Contestan que están de acuerdo: ya lo he actualizado en la agenda. También hay un mensaje de X marcado como urgente. żSe lo leo?
U: No, luego...
AA: Y seis mensajes más que he catalogado provisionalmente como propaganda.
U: Hm... żEl examen del curso de fiscalidad?
AA: Lo han devuelto corregido... No ha alcanzado usted el nivel mínimo. Lo siento
U: Bueno...
AA: Sobre el tema que me indicó he localizado cuatro noticias y un artículo: lo tiene todo traducido y preparado. Una de ellas tiene un grado de pertinencia absoluto. żSe la resumo?
U: Sí, pero un momento: żno me han contestado de Z?
AA: No. żLes escribo de nuevo?
U: Sí: mételes más prisa. żAlgo más?
AA: Sí: el correo de su hijo pequeńo. Uno de sus corresponsales está empleando expresiones obscenas.
U: ˇVaya! Déjamelo ver... ˇUn momento: antes de que se me olvide! Reserva una habitación doble en la costa para el fin de semana: vistas al mar, si es posible en un piso bajo. ˇY en una zona que se coma bien!
No se trata en absoluto de ciencia ficción: todos los procedimientos que entran en juego en esta escena ya existen, en diversos grados de desarrollo, aunque sin integrar (y aún no podemos crear sistemas de interacción tan sutiles como nuestro Agente Automático, pero podremos).
żQué hemos presenciado? En resumen: sistemas automáticos de comprensión y producción de la lengua natural (hablada y escrita), de traducción a y desde ella, y de relación con otros sistemas automáticos (por ejemplo, de venta)
[3].Las tecnologías lingüísticas implicadas son de dos tipos: por una parte están las facilitadoras de comunicación y transacciones generales (actúan como interfaz con el ordenador personal del usuario, y a través de él con bases de datos y sistemas de compra); por otra parte las que tienen una función directamente lingüística: comprensión, escritura, traducción, resumen...
Inmediatamente voy a tratar de describir qué sistemas de datos y programas lingüísticos deben existir para que sean posible unos procesos automáticos como los descritos. Veremos también cómo se entrecruzan con otras tecnologías informáticas y a qué tipos de productos dan lugar.
Tecnología lingüística y productos finalesVoy a intentar explicar a un público no necesariamente experto en tecnologías lingüísticas los componentes fundamentales de este campo. Creo que el alcance que se consiga bien vale la forzosa simplificación de algunos conceptos.
Elementos de base (investigación precompetitiva)
Todos estos elementos deben existir antes de que un programa haga ninguna función de tipo lingüístico. Pero por sí mismos no tienen un uso, ni son comercializables directamente.
diccionarios morfológicos (lematización/flexión). Relacionan conduje con conducir y ampliamente con amplio.
tesauros (redes semánticas). Dicen que tanto silla como taburete son muebles, que desembocadura y lecho son partes del río, y que zumo y jugo a veces significan lo mismo.
diccionarios sintácticos / reglas sintácticas (para análisis y síntesis). Informan de que tras las palomas el adjetivo blanco debe tener la forma blancas; el verbo informar exige la preposición de: le informo de que ... Relacionan el perro mordió al nińo con el nińo fue mordido con el perro; en la frase el policía vio al chico que las personas que estaban en la fiesta acusaron del crimen deducen que el acusado del crimen fue el chico.
diccionarios enciclopédicos (antropónimos, topónimos, siglas, ...). Para saber que Francia es un país y una república, que Jorge suele ser un nombre de varón, etc.
diccionarios multilingües. Informan de que lápiz es pencil en inglés, y viceversa.
bancos de datos terminológicos. Para conocimiento del vocabulario especializado en una disciplina, actividad técnica, etc.
Todavía de bajo nivel, pero utilizando algunos de los constituyentes anteriores están los:
desambiguadores. Analizan el contexto en el que aparece una palabra o expresión con más de un sentido, para saber cuál es el aplicable. Por ejemplo las gafas: żse trata de un artículo más un sustantivo o de un pronombre más el presente del verbo gafar?
Módulos orientados a tareas
Estos componentes ya suelen estar incorporados a productos comerciales, aunque por lo general no funcionan aisladamente, sino en el seno de un programa que hace otras cosas (éste lo indicamos entre paréntesis):
Correctores ortográficos. Informan de lo inaceptable de cirquense o inflacción (procesadores de textos)
Correctores gramaticales. Proponen en vez de el nińo que su padre es bombero, el nińo cuyo padre es bombero (procesadores de textos)
Correctores estilísticos. Recomiendan no usar pienso de que, evitan frases demasiado largas o ramificadas, y en general controlan la legibilidad de un texto (procesadores de textos)
Subsanadores de errores de entrada. Reconocen celentéreo bajo la forma incorrecta cerentéleo (programas de búsqueda)
Indizadores. En la frase Cada uno de los tres componentes principales del motor de ignición que hemos venido estudiando durante las últimas semanas seleccionan motor, ignición y componentes, por ese orden, como sus constituyentes clave (programas de búsqueda).
Resumidores de documentos. Permiten extraer de un texto de varias páginas un párrafo que resume su contenido (programas de búsqueda).
Conversores texto-habla/habla-texto. Permiten que un sistema automático produzca oralmente una determinada frase, o bien dictar de viva voz y que el sistema automático escriba (sistemas operativos, programas de dictado).
Traductores. A partir de un texto en una lengua producen otro en una lengua diferente (programas traductores, de búsqueda)
Productos
Son los que llegan al usuario final (corporativo o individual). Marcamos con * los que ponen en juego capacidades multilingües
Sistemas operativos. Para dirigirse (oralmente o por escrito) a los sistemas automáticos, y ser entendido por ellos. Para que ellos puedan contestar al usuario.
Procesadores de texto. Para que corrijan y ayuden al usuario.
* Programas de ayuda a la traducción. Para acceder al significado de textos en lenguas desconocidas.
* Buscadores (en la Red). Como ayuda para formular peticiones. Como filtro para discernir entre numerosas informaciones concurrentes. Para para adaptar contenidos brutos de bases de datos de conocimiento a los niveles del usuario.
* Comercio electrónico (entrada/salida de datos lingüísticos). Como ayuda para formular búsquedas y comunicar parámetros y requisitos. Para transmitir los hallazgos al usuario.
Enseńanza y formación a distancia. Para refinar el acceso automático a bases de datos de contenidos, para permitir respuestas abiertas y hacer juicios sobre progresión, para automatizar ciertos niveles de tutoría.
* Enseńanza de espańol como lengua extranjera. Todo lo incluido en el punto anterior más herramientas lexicográficas, de corrección de la expresión, de exploración semántica, ...
* Agentes inteligentes. Para comprender las peticiones (incluso fuzzy) de los usuarios, recorrer la red, buscar de acuerdo con los parámetros recibidos, comparar según los objetivos, y crear informes para el usuario. Para aprender del uso que el usuario hace de la información.
* Plataformas de edición. Para crear materiales escritos y auditivos con destino a determinados perfiles de usuario. No las usarán sólo las empresas editoriales y periodísticas, sino también las de enseńanza y todas las que requieran sistemas de comunicación en el interior de sus organizaciones.
* Asistentes terminológicos. Para entender, traducir o crear documentos científicos o técnicos.
Gestores / analizadores de información. Para recuperar información contenida en los registros de una empresa o de un usuario. Para filtrar documentos o correo (en el hogar, en el interior de empresas), para tareas de espionaje (industrial, político) [4]
Estimación económica
En los pantanosos terrenos de las estimaciones macroeconómicas cunde un curioso lema, que haré provisionalmente mío: "Más vale una estimación errada que la falta de cualquier estimación".
No es precisamente mi oficio hacer estas cosas, pero como nadie parece lanzarse a ello, empuńo la hoja de cálculo y pongo manos a la obra. No intentaré tanto llegar a cifras definitivas (żquién podría?), como marcar presencias, productos, tendencias que otros deberán precisar con mejores herramientas. He tratado siempre de hacer explícitas mis fuentes y mis supuestos.
Metodología
Mi estimación tiene dos ejes: por una parte voy a intentar otorgar un peso en tecnología lingüística (PTL) a cada uno de los productos o servicios estudiados. Lo aclararé con un ejemplo: un procesador de textos no es sólo un artefacto para colocar letras una tras otra. Tiene también saberes ortotipográficos (colocar guiones) y lingüísticos (corrector ortográfico, estilístico, diccionarios, etc). que hoy por hoy no constituyen productos independientes (aunque en ciertas épocas lo fueron, y en otras pueden volverlo a ser).
żCómo medir su importancia económica? Reflexionemos: en una hipotética concurrencia con otros productos idénticos en todo, pero que carecieran de esas tecnologías lingüísticas ańadidas, żcuál tendría mayor valor en el mercado? Por supuesto el más completo.
żCómo precisar este peso en tecnología lingüística? Mediante un índice, que denomino PTL. A grandes rasgos, dicho peso depende del producto: un programa traductor hace uso muy grande de tecnologías lingüísticas (aunque nunca un 100%, porque también utiliza tecnologías puramente informáticas). Un buscador avanzado para la red hará un uso mucho menor (porque la mayoría de su utilidad está en los programas de rastreo, en la base de datos de resultados, etc.), y así sucesivamente.
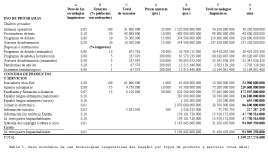
Mis hipótesis sobre el peso de las tecnologías lingüísticas se resumen en la Tabla 1 (la explicación de los distintos conceptos seguirá más adelante):
| Producto/servicio | PTL |
| Comercio electrónico | 0,01 |
| Industria del copyright | 0,01 |
| Información turística | 0,03 |
| Sistemas operativos | 0,05 |
| Enseńanza y formación a distancia | 0,07 |
| Procesadores de texto | 0,10 |
| Materiales de espańol lengua extranjera | 0,10 |
| Información (no turística) | 0,10 |
| Plataformas de edición | 0,20 |
| Buscadores en la Red | 0,30 |
| Gestores de información | 0,50 |
| Agentes inteligentes | 0,80 |
| Programas de dictado | 0,80 a 0,90 |
| Programas de ayuda a la traducción | 0,90 |
| Asistentes terminológicos | 0,90 |
Tabla 1. Peso de tecnologías lingüísticas por producto o servicio, ordenado por importancia creciente
Por otra parte nos interesará llegar a una estimación sobre el total de consumo que se hará de estos productos finales en un periodo de tiempo dado. Para ello seguiremos dos estrategias distintas, según estudiemos los programas o los restantes productos y servicios. Hay que advertir que para las estimaciones nos situaremos en un punto del futuro cercano, que podemos situar en torno al ańo 2004.
Los datos de los apartados inmediatos remitirán a la Tabla 3.
Programas
Intentaremos llegar al total de usuarios de cada uno (columna C), que estimamos como porcentaje del total de usuarios con ordenador. Para esta última cifra se ha tomado el dato de 61 millones de hispanohablantes con acceso a la Internet en el 2003/2004 [5]. Sabemos que parte de esta base de usuarios utilizará teléfonos móviles, web-TVs, agendas y libros electrónicos, etc. En la medida en que estos dispositivos tendrán capacidad de procesamiento y requerirán interfaces lingüísticas con el usuario, las englobamos en la misma categoría de "ordenador".
El porcentaje de usuarios de cada programa sobre el total de usuarios de ordenador (B) será alto en productos de uso general (procesador de textos) y va bajando en programas más específicos. La principal apuesta que hacemos es el uso extendido de gestores de información (que estimamos en un 30% de los usuarios con ordenador).
Para los precios de venta (D) hemos hecho una estimación basada en precios actuales, más estimación propia en los productos aún no comercializados [6] (gestores de información) . Los totales de usuarios (C) se multiplican por ellos para dar la facturación total (E), que multiplicado por el índice PTL (A) nos da el peso económico de las tecnologías lingüísticas por producto (F). Consideraremos un ciclo de 3 ańos, con una sola compra de todos estos productos, con lo que los resultados pasan directamente al total en el ciclo (H).
En el caso de las empresas e instituciones, a efectos de compra de programas las consideramos incluidas en los 61 millones de usuarios generales (véase más arriba), pero estimamos aparte sus equipamientos profesionales. Para ello partimos de un horizonte de casi 7 millones de unidades en el mundo hispanohablante [7]. Hemos asignado también un porcentaje de instituciones usuarias a cada tipo de programa.
Productos y servicios
Dada la muy diferente naturaleza de estos elementos, debemos ir analizándolos por separado. Como estamos planteándonos un periodo de 3 ańos, los totales (F) se multiplicarán por 3 (no consideramos incremento anual) para ingresar en la columna Total del ciclo (H).
Buscadores en la Red. Los buscadores no cobran (ni es previsible que cobren) sus servicios, pero obtienen ingresos indirectos por publicidad, o ceden sus servicios a comunidades profesionales, etc. (véase antes, nota 6). Aquí he estimado una cifra de negocios anual, de la que atribuyo el correspondiente porcentaje a tecnologías lingüísticas.
Agentes inteligentes. De nuevo, sólo se puede hacer una previsión de implantación y precio.
Enseńanza y formación a distancia. Sector económico de importancia creciente, pero sobre el que no he encontrado cuantificación. Sólo he podido hacer una estimación de cuántas personas podrían hacer uso de algún producto, y a qué precio.
Enseńanza de espańol lengua extranjera. Partimos de un número estimado de 43.000.000 de estudiantes de espańol en todo el mundo [8]. Una opinión autorizada que recogí hace ocho ańos calculaba el gasto mínimo en 40 dólares por alumno y ańo [9] sólo en materiales (es decir: sin contar matrículas ni gastos de escolaridad). Lo he actualizado a 50 dólares, lo que nos da un total de 387.000 millones de pesetas. A ello habría que ańadir los cursos impartidos directamente por línea, que cifro en otros 2.185 millones anuales [10].
Información turística. Para calibrarla hemos partido del número de visitantes a los países hispanohablantes con más turismo (Espańa, México y Argentina) [11]. Si el 10% de los viajes obtienen sus datos de fuentes electrónicas, y ciframos en 500 pta el costo de cada operación, obtenemos el total de la columna E.
Información profesional. Partimos de los datos de Tomás Baiget, MSStudy II (Second Member States's Study of the markets for electronic information services in the European Economic Area). Spain: 1997/98 [12], que cifraba el total del ingreso de las empresas por información electrónica en ese periodo en 79.550 millones de pesetas [13]. Lo que estima es el mercado de la información electrónica (científico-técnica y comercial, financiera, servicios de noticias...) principalmente para uso profesional, distribuida en línea, CD-ROM, etc. Supondremos que esa cifra crecerá un 100% desde 1997/8 hasta el 2004 (horizonte de nuestra estimación), y que el mundo hispanohablante no espańol tendrá una actividad que iguale a la de Espańa.
Industria del copyright. Según datos de un estudio de la Fundación Autor de la SGAE [14] el peso total de las "industrias del copyright" sobre el PIB está en torno al 3,5% (hemos estimado el PIB de 1999 en 90,447 billones). Este sector agruparía la mayor parte de la actividad de cultura y ocio, a diferencia de la información profesional, que hemos considerado en el parágrafo anterior. Para el total de Latinoamérica estimaremos un total igual al espańol.
Comercio electrónico. Para su estimación, deberíamos considerar la cifra total de transacciones electrónicas intrahispánicas, es decir, a, desde y en los países hispanohablantes. Esta cifra será una parte del comercio electrónico mundial, difícil, pero interesante de determinar... Según Dataquest en el 2003 el comercio en la Red supondrá en EEUU casi 23 billones de pesetas, y cerca de 18 billones en Europa [15]. De ese total de 41 billones de pesetas, y a falta de dato alguno del peso de las operaciones intrahispánicas, sólo podemos hacer una estimación, que ciframos en el 7%.
Conclusión
Este esfuerzo cuantificador nos ha llevado (Tabla 3) a una cifra para un periodo de tres ańos: más de billón y medio de pesetas, es decir: más de medio billón al ańo. Nuestras cifras (bien lo sabemos) son tentativas en un terreno especialmente movedizo, pero casi tan importante como la cuantía total es haber podido abordar la tarea de recapitulación: reconocer dónde se van a esconder las tecnologías lingüísticas del futuro inmediato. żEl monto total? Vendrán correcciones a estos datos, pero ya se disminuya (aunque las estimaciones han sido conservadoras) o se aumente, la conclusión para mí es clara: las tecnologías lingüísticas ocultas en el medio digital son un sector de gran peso económico.
Un terreno estratégico
Pero además hay otra consideración que aumenta la importancia de estos datos, y es la siguiente: si estuviéramos hablando de un sector de menor importancia estratégica, la estimación de su mercado sólo conduciría a ver el negocio que podemos perder. Pero éste no es el caso: o Espańa y los países hispanohablantes se integran en la economía de las redes, o quedarán en una situación marginal. Y esa integración hará necesariamente uso de las tecnologías lingüísticas descritas. Fallar en este sector no sólo implica perder el negocio de las tecnologías lingüísticas en las redes, sino vernos forzados a pagar por hacer uso de ellas para comercializar muchos de nuestros productos por línea.
Pondré un ejemplo muy claro: si no entramos en desarrollos de tecnología lingüística podremos sin duda seguir desarrollando obras de referencia (como enciclopedias), bases de datos turísticas, etc. Podremos también seguir creando bienes y servicios que comercializar por las redes. Pero cuando una empresa espańola o mexicana quiera hacer llegar estos productos a sus públicos naturales tendrá que pagar regalías por uso de unas tecnologías lingúísticas que no poseerá.
Por eso, para el total de los países hispanohablantes, hay que considerar los siguientes escenarios.
Escenario 1: Todas las tecnologías lingüísticas en manos ajenas |
|
| Beneficios por las tecnologías de la lengua del espańol |
|
| Costo de las tecnologías lingüísticas para comercializar nuestros productos y servicios |
|
| Total anual | - N millones pta |
Escenario 2: Todas las tecnologías lingüísticas en manos propias |
|
| Beneficios por las tecnologías de la lengua del espańol |
|
| Costo de las tecnologías lingüísticas para comercializar nuestros productos y servicios |
|
| Total anual | M millones pta |
| Diferencia entre Escenario 1 y Escenario 2 |
|
Tabla 2: Diferencia anual para los países
hispanohablantes
entre la posesión o no de tecnologías lingüísticas del espańol
Podemos recapitular con un símil: las redes son las autopistas de los flujos de bienes y servicios digitales, pero las tecnologías ligadas a las lenguas de los usuarios serán los peajes obligatorios. Seguro que tenemos que conducir por ellas, pero además podemos estar recaudando en la cabina, o no... [16]
żPara quién?
żA quién pertenecerá este negocio? Una ojeada a la Tabla 3 permite discernir dos grupos: los programas que ya tienen versiones dominantes (sistemas operativos, procesadores de textos, programas de dictado, de traducción), y los otros programas y servicios que no están aún plenamente desarrollados (gestores de información, ayudas para cursos de espańol, para enseńanza y formación...). Si bien no parece probable que una empresa espańola (o de un país hispanohablante) implante un nuevo procesador de textos [17], las nuevas herramientas para trabajo en la red sí que representan una oportunidad. Lo mismo podría decirse de otros muchos sectores: parte de nuestra información turística, económica o legal podría caer en manos ajenas... o a lo mejor no. Nunca podremos dominar toda el área de enseńanza del espańol, pero żpor qué no ser los primeros en crear las herramientas digitales de base que otros deban seguir? Y un amplio etcétera.
No pretendo estimar ahora la cuota de mercado que aún podríamos obtener (y de la que dependerían los beneficios M de la Tabla 2), porque ello exigiría una indagación al menos tan extensa y trabajosa como la que llevamos realizada. Valga la cuantificación precedente para dar una muestra de la importancia global del sector.
Qué ocurre
żQué haría falta para poder entrar con fuerza en estos nuevos productos? Recordemos el panorama trazado: primero, son necesarios los "elementos de base", la investigación precompetitiva. Ésta existe, aunque muy repartida entre universidades y empresas, y con calidades muy desiguales. Los últimos ańos han visto cómo fondos comunitarios apoyaban importantes proyectos. Pero de hecho (y por razones muy complejas) estos desarrollos precompetitivos, pagados con dinero público, tienen una rara salida a empresas, y creo no exagerar al decir que en el sector privado se están duplicando esfuerzos y reinventando la pólvora, mientras hay desarrollos que están dormidos en proyectos o departamentos universitarios.
Paralelamente, se están creando, también con dinero público, nuevos e importantes recursos. Quizás el mejor de ellos sean los corpus de la Real Academia: los corpus son herramientas esenciales para el desarrollo de la investigación de base. Pero he aquí que la Academia ha pactado la "utilización del Banco de datos léxicos de la R.A.E. por parte de Microsoft con fines de estudio e investigación en el área del lenguaje natural" [18].
żTodo esto a cambio de qué? [19] żEs la hipotética mejora del espańol futuro motivo suficiente para esta cesión? żCuántas empresas hispanas con desarrollos en tecnologías de la lengua están trabajando también con estos corpus? żNo estaremos abriendo los bazos a Microsoft para que luego nos venda los productos que ha desarrollado apoyándose en nuestros recursos?
La acción de quienes deberían fomentar el desarrollo de este sector clave aparece confundido por seńuelos que no apuntan en la buena dirección. El Ministerio de Industria, por ejemplo, ha presentado la iniciativa estratégica "INFO XXI. La Sociedad de la Información para todos", según la que se están planeando invertir en los próximos tres ańos "fondos públicos superiores a 450.000 millones de pesetas" [20]. INFO XXI prevé --entre otras medidas-- la "potenciación del castellano en la red con el objetivo de alcanzar en tres ańos un 15 por 100 de los contenidos en nuestro idioma" (ahora habría entre un 1,5 y un 5%, según estimaciones) [21].
żEs esta "ocupación" de la red por el espańol en sí un factor positivo? Sólo en cuanto que indica una cierta "alfabetización digital" de los usuarios, aunque, żqué va a hacer el ministerio en ese sentido, cuando la iniciativa privada (espańola y extranjera) ya está facilitando la creación y alojamiento de páginas web de forma gratuita? Naturalmente, lo que habría que hacer es fomentar cualitativamente la presencia del espańol en la red, aunque, ello exigiría el esfuerzo (aún no realizado) de definir qué es calidad en ese contexto [22].
Qué se podría hacer
El camino para tener una presencia en el sector de las tecnologías de la lengua sería partir de una línea sólida de investigación, concentrar esfuerzos y que nuestras empresas sacaran productos estratégicos que cuanto antes se pudieran encontrar con las demandas del público. Pero no veo indicios de ello.
Hay varios caminos que se pueden tomar, pero se resumen en uno: la puesta real a disposición pública de la investigación precompetitiva. Es decir: abrir al uso de quien justifique una intención de desarrollo seria los corpus y otros recursos existentes en distintas instituciones. Abrir los bancos de datos terminológicos para que las empresas hispánicas puedan beneficiarse de su explotación. Fomentar y alentar específicamente las empresas y proyectos que apunten a la creación de industrias de la lengua espańola.
Conclusión
Creo que nuestras instituciones están siguiendo seńuelos erróneos, que nuestras empresas están --en el mejor de los casos-- empantanadas repitiendo desarrollos que con toda probabilidad ya existen (generados a veces con dinero público), aportado escasos productos al mercado, y que mientras tanto las empresas extranjeras no descansan en sus esfuerzos por dotarse de tecnologías del espańol, a veces con el apoyo más bienintencionado que razonable de instituciones clave...
Hace dos ańos planteé públicamente algunas de estas cuestiones [23]. Meses después continuaba "según analicé hace poco (y nadie, desde la empresa o la investigación, me lo ha desmentido) lo más probable es que acabemos pagando a otros por hacer uso de nuestra lengua en las redes [24]".
Bien: ha vuelto a pasar el tiempo, y no se ven indicios de mejora ni desde las instituciones oficiales ni desde las empresas. Pero ahora, más o menos preciso, aporto un dato: el medio billón de pesetas anuales que está en juego dependiendo de nuestra postura ante las industrias de la lengua. Sería interesante que los responsables de políticas de investigación y desarrollo explicaran públicamente si creen que habrá algo para nosotros.
Notas
[2] Germán Bleiberg, Antología de elogios de la lengua espańola, Madrid, Cultura Hispánica, 1951.